
Tuning Java DB
Version 10.5
Derby Document build:
July 29, 2009, 11:16:10 AM (EDT)

Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright [yyyy] [name of copyright owner] Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
• | Performance tips and tricks Quick tips on how to improve the performance of Derby applications. | |
• | Tuning databases and applications A more in-depth discussion of how to improve the performance of Derby applications. | |
• | DML statements and performance An in-depth study of how Derby executes queries, how the optimizer works,
and how to tune query execution. | |
• | ||
• | Internal language transformations Reference on how Derby internally transforms some SQL statements
for performance reasons. Not of interest to the general user. |
• | Use prepared statements with substitution parameters to save
on costly compilation time. Prepared statements using substitution parameters
significantly improves performance in applications using standard statements. | |
• | Create indexes, and make sure they are being used. Indexes
speed up queries dramatically if the table is much larger than the number
of rows retrieved. | |
• | Increase the size of the data page cache and prime
all the caches. | |
• | Tune the size of database pages. Using
large database pages has provided a performance improvement of up to 50%. There are also other storage parameters worth tweaking. If
you use large database pages, increase the amount of memory available to Derby. | |
• | ||
• | ||
• | Tune database booting/class loading. System
startup time can be improved by reducing the number of databases in the system
directory. | |
• | Avoid inserts in autocommit mode if possible. Speed
up insert performance. | |
• | Customize the optimizer methods for table functions. Force
more efficient join orders for queries which use table functions. |
• | The page (user data) cache (described above)
Prime this cache by selecting
from much-used tables that are expected to fit into the data page cache. | |
• | The data dictionary cache
The cache that holds information stored
in the system tables. You can prime this cache with a query that selects from
commonly used user tables. | |
• | The statement cache
The cache that holds database-specific Statements (including PreparedStatements). You
can prime this cache by preparing common queries ahead of time in a separate
thread. |
• | You are storing large objects. | |
• | You have very large tables (over 10,000 rows).
For very large tables,
large pages reduces the number of I/Os required. | |
• | For read-only applications, use a large page size (for example, 32K) with
a pageReservedSpace of 0. |
derby.storage.pageSize=8192
• | Selective Queries If your application's
queries are very selective and use an index, large page size does not provide
much benefit and potentially degrades performance because a larger page takes
longer to read. |
• | Limited memory Large database pages reduce
I/O time because Derby can access more data with fewer I/Os. However,
large pages require more memory. Derby allocates a bulk number of database
pages in its page cache by default. If the page size is large, the system
might run out of memory. Here's a rough guideline: If the system
is running Windows 95 and has more than 32 MB (or Windows NT and has more
than 64 MB), it is probably beneficial to use 8K rather than 4K as the default
page size. Use the -mx flag as an optional parameter
to the JVM to give the JVM more memory upon startup. For example:
| |
• | Limited disk space If you cannot afford the
overhead of the minimum two pages per table, keep your page sizes small. |
SELECT DISTINCT nonIndexedCol FROM HugeTable SELECT * FROM HugeTable ORDER BY nonIndexedColumn
Recommended getXXX Method | java.sql.Types | SQL types |
getLong | BIGINT | BIGINT |
getBytes | BINARY | CHAR FOR BIT DATA |
getBlob | BLOB | BLOB |
getString | CHAR | CHAR |
getClob | CLOB | CLOB |
getDate | DATE | DATE |
getBigDecimal | DECIMAL | DECIMAL |
getDouble | DOUBLE | DOUBLE PRECISION |
getDouble | FLOAT | DOUBLE PRECISION |
getInt | INTEGER | INTEGER |
getBinaryStream | LONGVARBINARY | LONG VARCHAR FOR BIT DATA |
getAsciiStream, getUnicodeStream | LONGVARCHAR | LONG VARCHAR |
getBigDecimal | NUMERIC | DECIMAL |
getFloat | REAL | REAL |
getShort | SMALLINT | SMALLINT |
getTime | TIME | TIME |
getTimestamp | TIMESTAMP | TIMESTAMP |
getBytes | VARBINARY | VARCHAR FOR BIT DATA |
getString | VARCHAR | VARCHAR |
None supported. You must use XMLSERIALIZE and then the
corresponding getXXX method. | SQLXML | XML |
• | Run in autocommit false mode, execute a number of inserts in one transaction,
and then explicitly issue a commit. | |
• | If your application allows an initial load into the table, you can use
the import procedures to insert data into a table. Derby will
not log the individual inserts when loading into an empty table using these
interfaces. See the Java DB Tools and Utilities Guide Guide for
more information on the import procedures. |
• | When you define a primary key, unique, or foreign key constraint on a
table. See "CONSTRAINT clause" in the Java DB Reference Manual for
more information. | |
• | When you explicitly create an index on a table with a CREATE INDEX statement. |
• | If all the data requested are in the index, Derby does
not have to go to the table at all. (See Covering indexes.) | |
• | For operations that require a sort (ORDER BY), if Derby uses
the index to retrieve the data, it does not have to perform a separate sorting
step for some of these operations in some situations. (See About the optimizer's choice of sort avoidance.) |
select ht.hotel_id, ha.stay_date, ht.depart_time from hotels ht, Hotelavailability ha where ht.hotel_id = ha.hotel_id and ht.room_number = ha.room_number and ht.bed_type = 'KING' and ht.smoking_room = 'NO' order by ha.stay_date
-- would benefit from an index like this: -- CREATE INDEX c_id_desc ON Citites(city_id DESC) SELECT * FROM Cities ORDER BY city_id DESC -- would benefit from an index like this: -- CREATE INDEX f_miles_desc on Flights(miles DESC) SELECT MAX(miles) FROM Flight -- would benefit from an index like this: -- CREATE INDEX arrival_time_desc ON Flights(dest_airport, arrive_time DESC) SELECT * FROM Flights WHERE dest_airport = 'LAX' ORDER BY ARRIVAL DESC
SELECT * FROM ExtremelyHugeTable ORDER BY unIndexedColumn
• | Use client-side checking to make sure some minimal fields are always filled
in. Eliminate or disallow queries that cannot use indexes and are not optimizable.
In other words, force an optimizable WHERE clause by making sure that the
columns on which an index is built are included in the WHERE clause of the
query. Reduce or disallow DISTINCT clauses (which often require sorting) on
large tables. | |
• | For queries with large results, do not let the database do the ordering.
Retrieve data in chunks (provide a Next button to allow the user to retrieve
the next chunk, if desired), and order the data in the application. | |
• | Do not use SELECT DISTINCT to populate lists; instead, maintain a separate
table of the unique items. |
• | Your application can use PreparedStatements instead of Statements.
PreparedStatements are JDBC objects that you prepare (compile)
once and execute multiple times. See the figure below. If your application
executes statements that are almost but not exactly alike, use PreparedStatements,
which can contain dynamic or IN parameters. Instead of using the literals
for changing parameters, use question marks (?) as placeholders for such parameters.
Provide the values when you execute the statement. |
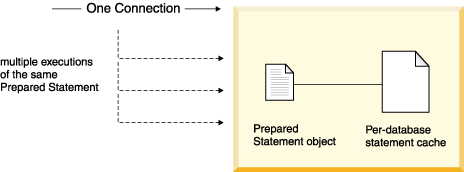
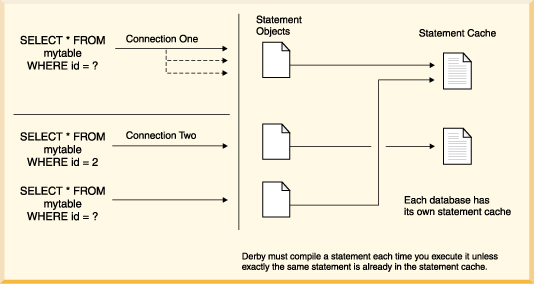
• | Even if your statement uses Statements instead of PreparedStatements, Derby can reuse the statement
execution plan for the statements from the statement cache. Statements from
any connection can share the same statement execution plan, avoiding compilation,
by using the single-statement cache. The statement cache maintains statement
plans across connections. It does not, however, maintain them across reboots.
See the figure below. When, in the same database, an application submits
an SQL Statement that exactly matches one already in the cache, Derby grabs the statement from
the cache, even if the Statement has already been closed by the application. To
match exactly with a statement already in the cache, the SQL Statement must
meet the following requirements:
|
• | When the system boots The system boots when you load the embedded
driver, org.apache.derby.jdbc.EmbeddedDriver. In a server framework,
the system boots when you start the server framework. Booting Derby loads
basic Derby classes. | |
• | When the first database boots Booting the first database loads
some more Derby classes.
The default behavior is that the first database boots when the first connection
is made to it. You can also configure the system to boot databases at startup.
Depending on your application, one or the other might be preferable. | |
• | When you compile the first query Compiling the first query
loads additional classes. |
Tuning tips for multi-user systems
|
Tuning tips for single-user systems
|
1.
| Collect your application's most frequently used SQL statements
and transactions into a single test. | |
2.
| Create a benchmark test suite against which to run the sample queries.
The first thing the test suite should do is checkpoint data (force Derby to
flush data to disk). You can do that with the following JDBC code:
| |
3.
| Use performance timings to identify poorly performing queries.
Try to distinguish between cached and uncached data. Focus on measuring operations
on uncached data (data not already in memory). For example, the first time
you run a query, Derby returns
uncached data. If you run the same query immediately afterward, Derby is
probably returning cached data. The performance of these two otherwise identical
statements varies significantly and skews results. | |
4.
| Use RunTimeStatistics to identify tables that are scanned excessively.
Check that the appropriate indexes are being used to satisfy the query and
that Derby is choosing
the best join order. You can also set derby.language.logQueryPlan to true
to check whether indexes are being used or not. This property will is print
query plans in the derby.log file. See the
"Derby properties" section of
the Java DB Reference Manual for details on this property.
See Working with RunTimeStatistics for more
information. | |
5.
| Make any necessary changes and then repeat. | |
6.
| If changing data access does not create significant improvements,
consider other database design changes, such as denormalizing data to reduce
the number of joins required. Then review the tips in Application and database design issues. |
• | the length of the compile time and the execute time. This can help in benchmarking queries. | |
• | the statement execution plan. This is a description
of result set nodes, whether an index was used, what the join order was, how
many rows qualified at each node, and how much time was spent in each node.
This information can help you determine whether you need to add indexes or
rewrite queries. |
• | call SYSCS_UTIL.SYSCS_GET_RUNTIMESTATISTICS, which retrieves
the RUNTIMESTATISTICS information as formatted text | |
• | call SYSCS_UTIL.SYSCS_SET_XPLAIN_SCHEMA before executing your
statements, which causes
Derby
to store the RUNTIMESTATISTICS information in the SYSXPLAIN
database tables, which can then be queried
later to retrieve the data. |
• | To use the RUNTIMESTATISTICS attribute in ij,
turn on and off RUNTIMESTATISTICS using the SYSCS_UTIL.SYSCS_SET_RUNTIMESTATISTICS() system
procedure (see the Java DB Reference Manual for more information):
| |
• | Turn on statistics timing using the SYSCS_UTIL.SYSCS_SET_STATISTICS_TIMING system
procedure (see the Java DB Reference Manual for more information).
If you do not turn on statistics timing, you will see the statement execution
plan only, and not the timing information.
|
SELECT * FROM Countries
Statement Name: null Statement Text: select * from countries Parse Time: 20 Bind Time: 10 Optimize Time: 50 Generate Time: 20 Compile Time: 100 Execute Time: 10 Begin Compilation Timestamp : 2005-05-25 09:16:21.24 End Compilation Timestamp : 2005-05-25 09:16:21.34 Begin Execution Timestamp : 2005-05-25 09:16:21.35 End Execution Timestamp : 2005-05-25 09:16:21.4 Statement Execution Plan Text: Table Scan ResultSet for COUNTRIES at read committed isolation level using instntaneous share row locking chosen by the optimizer Number of opens = 1 Rows seen = 114 Rows filtered = 0 Fetch Size = 16 constructor time (milliseconds) = 0 open time (milliseconds) = 0 next time (milliseconds) = 10 close time (milliseconds) = 0 next time in milliseconds/row = 0 scan information: Bit set of columns fetched=All Number of columns fetched=3 Number of pages visited=3 Number of rows qualified=114 Number of rows visited=114 Scan type=heap start position: null stop position: null qualifiers: None optimizer estimated row count: 119.00 optimizer estimated cost: 69.35
SELECT Country FROM Countries WHERE Region = 'Central America'
Statement Name: null Statement Text: SELECT Country FROM Countries WHERE Region = 'Central America' Parse Time: 10 Bind Time: 0 Optimize Time: 370 Generate Time: 10 Compile Time: 390 Execute Time: 0 Begin Compilation Timestamp : 2005-05-25 09:20:41.274 End Compilation Timestamp : 2005-05-25 09:20:41.664 Begin Execution Timestamp : 2005-05-25 09:20:41.674 End Execution Timestamp : 2005-05-25 09:20:41.674 Statement Execution Plan Text: Project-Restrict ResultSet (2): Number of opens = 1 Rows seen = 6 Rows filtered = 0 restriction = false projection = true constructor time (milliseconds) = 0 open time (milliseconds) = 0 next time (milliseconds) = 0 close time (milliseconds) = 0 restriction time (milliseconds) = 0 projection time (milliseconds) = 0 optimizer estimated row count: 11.90 optimizer estimated cost: 69.35 Source result set: Table Scan ResultSet for COUNTRIES at read committed isolation level using instantaneous share row locking chosen by the optimizer Number of opens = 1 Rows seen = 6 Rows filtered = 0 Fetch Size = 16 constructor time (milliseconds) = 0 open time (milliseconds) = 10 next time (milliseconds) = 0 close time (milliseconds) = 0 next time in milliseconds/row = 0 scan information: Bit set of columns fetched={0, 2} Number of columns fetched=2 Number of pages visited=3 Number of rows qualified=6 Number of rows visited=114 Scan type=heap start position: null stop position: null qualifiers: Column[0][0] Id: 2 Operator: = Ordered nulls: false Unknown return value: false Negate comparison result: false optimizer estimated row count: 11.90 optimizer estimated cost: 69.35
SELECT * FROM t1 -- DERBY-PROPERTIES index = t1_c1 FOR UPDATE OF c2, c1
Statement Name: null Statement Text: select * from t1 --DERBY-PROPERTIES index = t1_c1 for update of c2, c1 Parse Time: 0 Bind Time: 0 Optimize Time: 0 Generate Time: 0 Compile Time: 0 Execute Time: 0 Begin Compilation Timestamp : null End Compilation Timestamp : null Begin Execution Timestamp : null End Execution Timestamp : null Statement Execution Plan Text: Index Row to Base Row ResultSet for T1: Number of opens = 1 Rows seen = 4 Columns accessed from heap = {0, 1, 2} constructor time (milliseconds) = 0 open time (milliseconds) = 0 next time (milliseconds) = 0 close time (milliseconds) = 0 User supplied optimizer overrides on T1 are { index=T1_C1 } Index Scan ResultSet for T1 using index T1_C1 at read committed isolation level using exclusive row locking chosen by the optimizer Number of opens = 1 Rows seen = 4 Rows filtered = 0 Fetch Size = 1 constructor time (milliseconds) = 0 open time (milliseconds) = 0 next time (milliseconds) = 0 close time (milliseconds) = 0 next time in milliseconds/row = 0 scan information: Bit set of columns fetched=All Number of columns fetched=2 Number of deleted rows visited=0 Number of pages visited=1 Number of rows qualified=4 Number of rows visited=4 Scan type=btree Tree height=1 start position: None stop position: None qualifiers: None
• | An index on the orig_airport column (called OrigIndex) | |
• | An index on the dest_airport column (called DestIndex) | |
• | An index enforcing the primary key constraint
on the flight_id and segment_number columns (which has a system-generated name) |
• | For every row in Flights, there is an entry in OrigIndex that includes the value of the orig_airport column and the address of the row itself. The entries are
stored in ascending order by the orig_airport values. |
'AA1111' 1 'AA1111' 2 'AA1112' 1 'AA1113' 1 'AA1113' 2
SELECT * FROM Flights WHERE orig_airport = 'SFO' SELECT * FROM Flights WHERE orig_airport < 'BBB' SELECT * FROM Flights WHERE orig_airport >= 'MMM'
SELECT * FROM Flights WHERE dest_airport = 'SCL'
SELECT * FROM Flights WHERE flight_id = 'AA1111' SELECT * FROM Flights WHERE flight_id BETWEEN 'AA1111' AND 'AA1115' SELECT * FROM FlightAvailability AS fa, Flights AS fts WHERE flight_date > CURRENT_DATE AND fts.flight_id = fa.flight_id AND fts.segment_number = fa.segment_number
SELECT * FROM Flights WHERE flight_id = 'AA1111' AND segment_number <> 2
• | It uses a simple column reference to a column (the name of the column,
not the name of the column within an expression or method call). For example,
the following is a simple column reference:
The following is not:
| |||||||||||||||||||
• | It refers to a column that is the first or only column in the index.
References to contiguous columns in other predicates
in the statement when there is a multi-column index can further define the
starting or stopping points. (If the columns are not contiguous with the first
column, they are not optimizable predicates but can be used as qualifiers.) For example, given a composite index on FlightAvailability (flight_id, segment_number, and flight_date), the following
predicate satisfies that condition:
The following
one does not:
| |||||||||||||||||||
• | The column is compared to a constant or to an
expression that does not include columns in the same table. Examples of valid
expressions: other_table.column_a, ? (dynamic parameter), 7+9. The comparison
must use the following operators:
|
• | BETWEEN | |
• | LIKE (in certain situations) | |
• | IN (in certain situations) |
SELECT * FROM Countries, Cities WHERE Countries.country_ISO_code = Cities.country_ISO_code
SELECT orig_airport FROM Flights SELECT DISTINCT lower(orig_airport) FROM Flights FROM Flights
-- Derby would scan entire table; comparison is not with a -- constant or with a column in another table SELECT * FROM Flights WHERE orig_airport = dest_airport -- Derby would scan entire table; <> operator is not optimizable SELECT * FROM Flights WHERE orig_airport <> 'SFO' -- not valid operator for matching index scan -- However, Derby would do an index -- rather than a table scan because -- index covers query SELECT orig_airport FROM Flights WHERE orig_airport <> 'SFO' -- use of a function is not simple column reference -- Derby would scan entire index, but not table -- (index covers query) SELECT orig_airport FROM Flights WHERE lower(orig_airport) = 'sfo'
-- the where clause compares both columns with valid -- operators to constants SELECT * FROM Flights WHERE flight_id = 'AA1115' AND segment_number < 2 -- the first column is in a valid comparison SELECT * FROM Flights WHERE flight_id < 'BB' -- LIKE is transformed into >= and <=, providing -- start and stop conditions SELECT * FROM Flights WHERE flight_id LIKE 'AA%'
-- segment_number is in the index, but it's not the first column; -- there's no logical starting and stopping place SELECT * FROM Flights WHERE segment_number = 2 -- Derby would scan entire table; comparison of first column -- is not with a constant or column in another table -- and no covering index applies SELECT * FROM Flights WHERE orig_airport = dest_airport AND segment_number < 2
SELECT * FROM FLIGHTS WHERE orig_airport < 'BBB' AND orig_airport <> 'AKL'
• | The following comparisons are valid qualifiers:
| |||||||||||||||||||||||||||||||
• | The qualifier's reference to the column does not have to be a simple
column reference; you can put the column in an expression. | |||||||||||||||||||||||||||||||
• | The qualifier's column does not have to be the first column in the
index and does not have to be contiguous with the first column in the index. |
SELECT * FROM Flights WHERE dest_airport < 'Z'
SELECT * FROM Flights WHERE dest_airport < 'B'
• | If the join has no restrictions in the WHERE clause that would limit the
number of rows returned from one of the tables to just a few, the following
rules apply:
| |||||||
• | On the other hand, if a query has restrictions in the WHERE clause for
one table that would cause it to return only a few rows from that table (for
example, WHERE flight_id = 'AA1111'), it is better for the restricted table
to be the outer table. Derby will have to go to the inner table only
a few times anyway.
Consider:
| |||||||
• | In this case, the qualification huge_table.unique_column
= 1 (assuming a unique index on the column) qualifies only one row, so
it is better for huge_table to be the outer table
in the join. |
• | It must use the = operator to compare column(s) in the outer table to
column(s) in the inner table. | |
• | References to columns in the inner table must be simple column references.
Simple column references are described in Directly optimizable predicates. |
• | Which index (if any) to use on each table in a query (see About the optimizer's choice of access path) | |
• | The join order (see About the optimizer's choice of join order) | |
• | The join strategy (see About the optimizer's choice of join strategy) | |
• | Whether to avoid additional sorting (see About the optimizer's choice of sort avoidance) | |
• | Automatic lock escalation (see About the system's selection of lock granularity) | |
• | Whether to use bulk fetch (see About the optimizer's selection of bulk fetch) |
• | The size of each table | |
• | The indexes available on each table | |
• | Whether an index on a table is useful in a particular join order | |
• | The number of rows and pages to be scanned for each table in each join
order |
SELECT * FROM FlightAvailability AS fa, Flights AS fts WHERE fa.flight_id = fts.flight_id AND fa.segment_number = fts.segment_number
SELECT * FROM FlightAvailability AS fa, Flights AS fts WHERE fa.flight_id = fts.flight_id AND fa.segment_number = fts.segment_number
• | statements with ORDER BY
|
• | sort avoidance for DISTINCT and GROUP BYs
| |
• | statements with a MIN() aggregate
|
• | The statements involve tables with indexes that are in the correct order. | |
• | The statements involve scans of unique indexes that are guaranteed to
return only one row per scan. |
• | Index scans, which provide the correct order.
| |
• | The rows from a table when fetched through an index scan.
| |
• | The rows from a join when ordered by the indexed column or columns in
the outer table.
| |
• | Result sets that are guaranteed to return a single row. They are ordered
on all of their columns (for example, if there are
equality conditions on all the columns in a unique index, all the columns
returned for that table can be considered ordered, with any priority of ordering
of the columns).
| |
• | Any column in a result set that has an equality comparison with a constant.
The column is considered ordered with no priority to its ordering.
And because of transitive
closure, this means that even more complex statements can avoid sorting. For
example:
For more information
about transitive closure and other statement transformations, see Internal language transformations. |
SELECT * FROM FlightAvailability AS fa, Flights AS fts WHERE fts.flight_id = fa.flight_id AND fts.segment_number = fa.segment_number
• | For SELECT statements running in READ_COMMITTED isolation, the system
always chooses row-level locking. | ||||
• | If the statement scans the entire table or index and it does not meet
the criteria above, the system chooses table-level locking. (A statement scans
the entire table whenever it chooses a table as the access path.) | ||||
• | If a statement partially scans the index, the system uses row-level locking,
until the number of rows touched on a table reaches lock escalation threshold.
It is then escalated to a table lock. (You can configure this threshold number;
see Lock escalation threshold.)
|
SELECT * FROM Flights WHERE miles > 4 SELECT * FROM Flights
• | Single table holding the majority of the locks
| ||||||||||||||||||||||
• | Two tables holding the majority of the locks
| ||||||||||||||||||||||
• | Many tables holding a small number of locks
|
CREATE TABLE t1(c1 INT, c2 INT, c3 INT, c4 INT) CREATE INDEX i1 ON t1(c1) CREATE INDEX i1_2_3_4 ON t1(c1, c2, c3, c4)
• | The SELECT list is composed entirely of simple column references and constants. | |
• | All simple column references come from the same table and the optimizer
has chosen the table in question to be the outermost table in the query block. | |
• | The optimizer has chosen an index as the access path for the table in
question. | |
• | The simple column references in the SELECT list, plus any simple column
references from the table that have equality predicates on them, are a prefix
of the index that the optimizer selected as the access path for the table. |
SELECT DISTINCT c1 FROM t1
SELECT DISTINCT c2 FROM t1 WHERE c1 = 5 SELECT DISTINCT c2, c4 FROM t1 WHERE c1 = 5 and c3 = 7 -- the columns don't have to be in the -- same order as the index SELECT DISTINCT c2, c1 FROM t1
• | There is a single table in the query block. | |
• | An ORDER BY clause is not merged into the DISTINCT. | |
• | All entries in the SELECT list are simple column references. | |
• | There are no predicates in the query block. |
• | All grouping columns come from the same table and the optimizer has chosen
the table in question to be the outermost table in the query block. | |
• | The optimizer has chosen an index as the access path for the table in
question. | |
• | The grouping columns, plus any simple column references from the table
that have equality predicates on them, are a prefix of the index that the
optimizer selected as the access path for the table. |
SELECT max(c2) FROM t1 GROUP BY c1
SELECT c2, SUM(c3) FROM t1 WHERE c1 = 5 GROUP BY c2 SELECT max(c4) FROM t1 WHERE c1 = 5 AND c3 = 6 GROUP BY c2
• | The MIN() or MAX() is the only entry in the SELECT list. | ||||||||||
• | The MIN() or MAX() is on a simple column reference, not on an expression. | ||||||||||
• | For MAX(), there must not be a WHERE clause. | ||||||||||
• | For MIN():
|
-- index on orig_airport SELECT MIN(orig_airport) FROM Flights -- index on orig_airport SELECT MAX(orig_airport) FROM Flights -- index on orig_airport SELECT miles FROM Flights WHERE orig_airport = (SELECT MIN(orig_airport) FROM Flights) -- index on segment_number, flight_id SELECT MIN(segment_number) FROM Flights WHERE flight_id = 'AA1111' SELECT * FROM Flights WHERE segment_number = (SELECT MIN(segment_number) FROM Flights WHERE flight_id = 'AA1111')
FROM [ -- DERBY-PROPERTIES joinOrder = { FIXED | UNFIXED } ] TableExpression [,TableExpression]*
{table-Name | view-Name } [ [ AS ] correlation-Name [ (Simple-column-Name [ , Simple-column-Name ]* ) ] ] [ -- DERBY-PROPERTIES { constraint = constraint-Name | index = index-Name | joinStrategy = { NESTEDLOOP | HASH } } ]
CREATE TABLE t1 (c1 int, c2 int, c3 int, CONSTRAINT cons1 PRIMARY KEY (c1, c2)) INSERT INTO t1 VALUES (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4) SELECT * FROM t1 --DERBY-PROPERTIES constraint=cons1 FOR UPDATE
CREATE TABLE t1 (c1 int, c2 int, c3 int, CONSTRAINT cons1 PRIMARY KEY (c1, c2)) INSERT INTO t1 VALUES (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4) CREATE INDEX t1_c1 ON t1(c1) SELECT * FROM t1 --DERBY-PROPERTIES index=t1_c1 WHERE c1=1
CREATE TABLE t1 (c1 int, c2 int, c3 int, CONSTRAINT cons1 PRIMARY KEY (c1, c2)) CREATE TABLE t2 (c1 int not null, c2 int not null, c3 int, CONSTRAINT cons2 UNIQUE (c1, c2)) INSERT INTO t1 VALUES (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4) INSERT INTO t2 VALUES (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4) SELECT * FROM --DERBY-PROPERTIES joinOrder=FIXED t1, t2 WHERE t1.c1=t2.c1
CREATE TABLE t1 (c1 int, c2 int, c3 int, CONSTRAINT cons1 PRIMARY KEY (c1, c2)) CREATE TABLE t2 (c1 int not null, c2 int not null, c3 int, CONSTRAINT cons2 UNIQUE (c1, c2)) INSERT INTO t1 VALUES (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4) INSERT INTO t2 VALUES (1, 1, 1), (2, 2, 2), (3, 3, 3), (4, 4, 4) SELECT * FROM --DERBY-PROPERTIES joinOrder=FIXED t1 a, t1 b --DERBY-PROPERTIES joinStrategy=NESTEDLOOP WHERE a.c1=b.c1
• | The optimizer knows "exactly" the number of rows that will be
scanned from disk for table scans (see Determinations of rows scanned from disk for a table scan). | |
• | For index scans, the optimizer must estimate the number of rows that will
be scanned from disk. (see Estimations of rows scanned from disk for an index scan). Derby might
be able to use cardinality statistics to make a better estimate of the number
of rows that will be scanned from disk as described in this chapter. |
SELECT * FROM Flights
SELECT * FROM Flights WHERE orig_airport = 'SFO'
-- there's a unique key on city_id SELECT * FROM Cities WHERE city_id = 1
-- dynamic parameters SELECT * FROM Flights WHERE orig_airport = ? rollback -- joins SELECT * FROM Countries, Cities WHERE Countries.country_ISO_code = Cities.country_ISO_code -- complex search conditions SELECT * FROM Countries WHERE region = (select region from Countries where country = 'Spain')
• | The statistics exist | |
• | The relevant columns in the WHERE column are leading columns in an index | |
• | The columns are compared to values using only the = operator | |
• | Statistics are not turned off in the system or query |
Operator | Selectivity |
=, >=, >, <=, <, <> when data type of
parameter is a boolean | .5 (50%) |
other operators (except for IS NULL and IS NOT NULL) when
data type of parameter is boolean | .5 (50%) |
IS NULL | .1 (10%) |
IS NOT NULL | .9 (90%) |
= | .1 (10%) |
>, >=, <, <= | .33 (3%) |
<> compared to non-boolean type | .9 (90%) |
LIKE transformed from LIKE predicate (see LIKE transformations) | 1.0 (100%) |
>= and < when transformed internally from LIKE (see LIKE transformations) | .25 (.5 X .5) |
>= and <= operators when transformed internally from
BETWEEN (see BETWEEN transformations) | .25 (.5 X .5) |
• | The number of rows in the table | |
• | The number of unique values for a set of columns for leading columns in
an index key, also known as cardinality. Leading columns
refers to the first column, or the first and second column, or the first,
second, and third column of an index (and so on). Derby cannot compute
the number of columns for which a combination of the non-leading columns is
unique. |
CONSTRAINT FLIGHTAVAILABILITY_PK Primary Key ( FLIGHT_ID, SEGMENT_NUMBER, FLIGHT_DATE)
• | The number of rows in the table FlightAvailability | |
• | The number of unique rows for the full key (flight_id, segment_number, flight_date) | |
• | The number of unique rows for the key (flight_id, segment_number) | |
• | The number of unique rows for the key (flight_id) |
SELECT * FROM Flights, FlightAvailability WHERE Flights.flight_id = OtherTable.flight_id
((Rows in Flights) * (Rows in OtherTable))/250
• | When you create a new index on an existing non-empty table. Statistics
are automatically created for only the new index. | |
• | When you add a primary key, unique, or foreign key constraint to an existing
non-empty table. If there is no existing index that can be used for the new
key or constraint, Derby automatically
creates statistics for only the new indexes. | |
• | When you run the SYSCS_UTIL.SYSCS_COMPRESS_TABLE system procedure. Statistics
are created automatically for all indexes if the statistics do not already
exist. | |
• | When you drop a column that is part of a table's index, the statistics
for the affected index are dropped. Statistics are automatically updated for
the other indexes on the table. |
This chapter uses some specialized terms. Here are some
definitions: base table A real table in a FROM list. In queries that involve "virtual"
tables such as views and derived tables, base tables are the underlying tables
to which virtual tables correspond. derived table A virtual table, such as a subquery given a correlation name or a view.
For example: SELECT derivedtable.c1 FROM (VALUES ('a','b'))
AS derivedtable(c1,c2). equality predicate A predicate in which one value is
compared to another value using the = operator. equijoin predicate A predicate in which one column is compared to a column in another table
using the = operator. optimizable A predicate is optimizable if it provides a
starting or stopping point and allows use of an index. Optimizable predicates
use only simple column references and =, <, >, +, >=,
and IS NULL operators. For complete details, see What's optimizable?. A synonym for optimizable is indexable. predicate A WHERE clause contains boolean expressions that can be linked together
by AND or OR clauses. Each part is called a predicate.
For example: WHERE c1 =2 AND c2 = 5 contains two predicates. sargable Sargable predicates are a superset of optimizable
predicates; not all sargable predicates are optimizable, because sargable
predicates also include the <> operator. (Sarg stands
for "search argument.") Predicates that are sargable but not optimizable
nevertheless improve performance and allow the optimizer to use more accurate
costing information.
In addition, sargable predicates can be pushed down (see Predicates pushed into views or derived tables). simple column reference A reference to a column that is not part of an expression. For example, c1 is a simple column reference, but c1+1,max(c1), and lower(c1) are not. |
SELECT * FROM Flights WHERE flight_id = 'AA1111' AND segment_number <> 2
country LIKE 'Ch%i%'
country LIKE 'Chile'
country LIKE ?
country LIKE ? AND country >= InternallyGeneratedParameter AND country < InternallyGeneratedParameter
(country || '') LIKE ?
orig_airport IN ('ABQ', 'AKL', 'DSM') orig_airport IN (?, ?, ?) orig_airport IN ('ABQ', ?, ?, 'YYZ')
orig_airport = ?
1.
| There must be an index defined on the table that the column reference
belongs to, and the column reference must be the first column in the index.
In the example above, orig_airport is the column reference. | |
2.
| The estimated cost of an access path that uses the probe predicate and
one of the corresponding indexes must be less than the estimated cost of any
other access paths calculated by the optimizer. Typically, this means that
the number of values in the IN list is significantly fewer than the number
of rows in the table that the column reference belongs to. |
SELECT flights.orig_airport, cities.city_name FROM flights, cities WHERE flights.orig_airport IN ('ABQ', 'DSM', 'YYZ') AND flights.orig_airport = cities.airport
SELECT flights.orig_airport, cities.city_name FROM flights, cities WHERE flights.orig_airport = ? AND flights.orig_airport = cities.airport
PreparedStatement ps = conn.prepareStatement( "select flights.orig_airport, cities.city_name " + "from flights, cities " + "where flights.orig_airport = ? " + "and flights.orig_airport = cities.airport "); ps.setString(1, "ABQ"); rs1 = ps.executeQuery(); ps.setString(1, "DSM"); rs2 = ps.executeQuery(); ps.setString(1, "YYZ"); rs3 = ps.executeQuery();
SELECT flights.orig_airport, cities.city_name FROM flights, cities WHERE flights.orig_airport = 'ABQ' AND flights.orig_airport = cities.airport UNION ALL SELECT flights.orig_airport, cities.city_name FROM flights, cities WHERE flights.orig_airport = 'DSM' AND flights.orig_airport = cities.airport UNION ALL SELECT flights.orig_airport, cities.city_name FROM flights, cities WHERE flights.orig_airport = 'YYZ' AND flights.orig_airport = cities.airport
orig_airport NOT IN ('ABQ', 'AKL', 'DSM')
simple column reference = Expression
simple column reference IN (Expression1, Expression2, ..., ExpressionN)
SELECT * FROM Flights WHERE flight_id = 'AA1111' OR flight_id = 'US5555' OR flight_id = ?
• | Transitive closure on join clauses
Applied first, if applicable | |
• | Transitive closure on search clauses |
SELECT * FROM samp.employee e, samp.emp_act a, samp.emp_resume r WHERE e.empno = a.empno and a.empno = r.empno
SELECT * FROM samp.employee e, samp.emp_act a, samp.emp_resume r WHERE e.empno = a.empno and a.empno = r.empno and e.empno = r.empno
SELECT * FROM Flights, FlightAvailability WHERE Flights.flight_id = FlightAvailability.flight_id AND Flights.flight_id between 'AA1100' and 'AA1250' AND Flights.flight_id <> 'AA1219' AND FlightAvailability.flight_id <> 'AA1271'
• | the BETWEEN transformation on the second predicate:
|
SELECT * FROM Flights, FlightAvailability WHERE Flights.flight_id = FlightAvailability.flight_id AND Flights.flight_id >= 'AA1100' AND Flights.flight_id <= 'AA1250' AND Flights.flight_id <> 'AA1219' AND Flights.flight_id <> 'AA1271' AND FlightAvailability.flight_id >= 'AA1100' AND FlightAvailability.flight_id <= 'AA1250' AND FlightAvailability.flight_id <> 'AA1271' AND FlightAvailability.flight_id <> 'AA1219'
SELECT * FROM Flights, Flightavailability WHERE Flights.flight_id = Flightavailability.flight_id AND Flightavailability.flight_id = 'AA1122'
• | The select list is composed entirely of simple column references and constants. | |
• | There is no GROUP BY clause in the view. | |
• | There is no DISTINCT in the view. |
SELECT Cities.city_name, Countries.country_iso_code FROM Cities, Countries WHERE Cities.country_iso_code = Countries.country_iso_code
SELECT a, b FROM v1 WHERE a = 'Melbourne'
SELECT a, b FROM (select Cities.city_name, Countries.country_iso_code FROM Cities, Countries WHERE Cities.country_iso_code = Countries.country_iso_code) v1(a, b) WHERE a = 'Melbourne'
SELECT Cities.city_name, Countries.country_iso_code FROM Cities, Countries WHERE Cities.country_iso_code = Countries.country_iso_code AND Cities.city_name = 'Melbourne'
CREATE VIEW v2(a,b) AS SELECT sales_person, MAX(sales) FROM Sales GROUP BY sales_person
SELECT * FROM v2 WHERE a = 'LUCCHESSI'
SELECT a, b FROM (SELECT sales_person, MAX(sales) FROM Sales WHERE sales_person = 'LUCCHESSI' GROUP BY sales_person) v1(a, b)
SELECT a, b FROM (SELECT sales_person, MAX(sales) from Sales WHERE sales_person = 'LUCCHESSI' GROUP BY sales_person) v1(a, b)
SELECT * FROM Staff WHERE id = (SELECT MAX(manager) FROM Org)
constant = SELECT MAX(manager) FROM Org SELECT * FROM Staff WHERE id = constant
In this example, the subquery x1 is noncorrelated because it does not reference any of the columns from the outer query. The subquery is nonflattenable because of the DISTINCT keyword. Derby does not flatten DISTINCT subqueries. This subquery is eligible for materialization. Since there is an equijoin predicate between the subquery x1 and the table t1 (namely, t1.i = x1.a), the Derby optimizer will consider performing a hash join between t1 and x1 (with x1 as the inner operand). If that approach yields the best cost, Derby materializes the subquery x1 to perform the hash join. The subquery is evaluated only a single time and the results are stored in an in-memory hash table. Derby then executes the join using the in-memory result set for x1.SELECT i, a FROM t1, (SELECT DISTINCT a FROM T2) x1 WHERE t1.i = x1.a AND t1.i in (1, 3, 5, 7)
c1 |
1 |
2 |
3 |
c1 |
2 |
2 |
1 |
SELECT c1 FROM t1 WHERE c1 IN (SELECT c1 FROM t2)
1 2
SELECT t1.c1 FROM t1, t2 WHERE t1.c1 = t2.c1 1 2 2
• | The subquery is not under an OR. | |
• | The subquery type is EXISTS, IN, or ANY, or it is an expression subquery
on the right side of a comparison operator. | |
• | The subquery is not in the SELECT list of the outer query block. | |
• | There are no aggregates in the SELECT list of the subquery. | |
• | The subquery does not have a GROUP BY clause. | |
• | There is a uniqueness condition that ensures that the subquery does not
introduce any duplicates if it is flattened into the outer query block. | |
• | Each table in the subquery's FROM list (after any view, derived table,
or subquery flattening) must be a base table. | |
• | If there is a WHERE clause in the subquery, there is at least one table
in the subquery whose columns are in equality predicates
with expressions that do not include any column references from the subquery
block. These columns must be a superset of the key columns for any unique
index on the table. For all other tables in the subquery, the columns in equality
predicates with expressions that do not include columns from the same table
are a superset of the unique columns for any unique index on the table. |
SELECT huge.* FROM huge WHERE c1 IN (SELECT c1 FROM tiny)
SELECT huge.* FROM huge, tiny WHERE huge.c1 = tiny.c1
CREATE TABLE t1 (c1 INT) CREATE TABLE t2 (c1 INT NOT NULL PRIMARY KEY) CREATE TABLE t3 (c1 INT NOT NULL PRIMARY KEY) INSERT INTO t1 VALUES (1), (2), (3) INSERT INTO t2 VALUES (1), (2), (3) INSERT INTO t3 VALUES (2), (3), (4)
SELECT t1.* FROM t1 WHERE t1.c1 IN (SELECT t2.c1 FROM t2, t3 WHERE t2.c1 = t3.c1)
2 3
SELECT t1.* FROM t1, t2, t3 WHERE t1.c1 = t2.c1 AND t2.c1 = t3.c1 AND t1.c1 = t3.c1
SELECT t1.* FROM t1 WHERE EXISTS (SELECT * FROM t2, t3 WHERE t2.c1 = t3.c1 AND t2.c1 = t1.c1)
SELECT t1.* FROM t1, t2, t3 WHERE t1.c1 = t2.c1 AND t2.c1 = t3.c1 AND t1.c1 = t3.c1
SELECT c1 FROM t1 WHERE c1 IN (SELECT c1 FROM t2)
SELECT c1 FROM t1, t2 WHERE t1.c1 = t2.c1 EXISTS JOIN INTERNAL SYNTAX
• | The subquery is not under an OR. | |
• | The subquery type is EXISTS, IN, or ANY. | |
• | The subquery is not in the SELECT list of the outer query block. | |
• | There are no aggregates in the SELECT list of the subquery. | |
• | The subquery does not have a GROUP BY clause. | |
• | The subquery has a single entry in its FROM list that is a base table. | |
• | None of the predicates in the subquery, including the additional one formed
between the left side of the subquery operator and the column in the subquery's
SELECT list (for IN or ANY subqueries), include any subqueries, method calls,
or field accesses. |
SELECT t1.* FROM t1, t2 WHERE EXISTS (SELECT * FROM t3 WHERE t1.c1 = t3.c1)
SELECT t1.* FROM t1, t2, t3 WHERE t1.c1 = t3.c1
SELECT * FROM t1 WHERE c1 IN (SELECT DISTINCT c2 FROM t2 WHERE t1.c3 = t2.c4) SELECT * FROM t1 WHERE c1 IN (SELECT c2 FROM t2 WHERE t1.c3 = t2.c4)
• | Simple VALUES clauses | |
• | SELECTs returning a non-grouped aggregate |
WHERE C1 IN (SELECT MIN(c1) FROM T)
WHERE C1 = (SELECT MIN(c1) FROM T)
Before Transformation | After Transformation |
c1 IN (SELECT ...) | c1 = (SELECT ...) |
c1 = ANY (SELECT ...) | c1 = (SELECT ...) |
c1 <> ANY (SELECT ...) | c1 <> (SELECT ...) |
c1 > ANY (SELECT ...) | c1 > (SELECT ...) |
c1 >= ANY (SELECT ...) | c1 >= (SELECT ...) |
c1 < ANY (SELECT ...) | c1 < (SELECT ...) |
c1 <= ANY (SELECT ...) | c1 <= (SELECT ...) |
• | No GROUP BY list. | |||||||
• | SELECT list contains at least one simple
column reference. | |||||||
• | Every simple
column reference is from the same table. | |||||||
• | Every table in the FROM list is a base
table. | |||||||
• | Primary table There is
at least one unique index on one table in the FROM list for which all the
columns appear in one of the following:
| |||||||
• | Secondary table(s) All
the other tables in the FROM list also have at least one unique index for
which all the columns appear in one of the following:
|
CREATE TABLE tab1 (c1 INT NOT NULL, c2 INT NOT NULL, c3 INT NOT NULL, c4 CHAR(2), PRIMARY KEY (c1, c2, c3)) CREATE TABLE tab2 (c1 INT NOT NULL, c2 INT NOT NULL, PRIMARY KEY (c1, c2)) INSERT INTO tab1 VALUES (1, 2, 3, 'WA'), (1, 2, 5, 'WA'), (1, 2, 4, 'CA'), (1, 3, 5, 'CA'), (2, 3, 1, 'CA') INSERT INTO tab2 VALUES (1, 2), (1, 3), (2, 2), (2, 3) -- all the columns in the index on the only table (tab1) appear -- in the way required for the Primary table (simple column references) SELECT DISTINCT c1, c2, c3, c4 FROM tab1 -- all the columns in the index on the only table (tab1) appear -- in the way required for the Primary table (equality predicates) SELECT DISTINCT c3, c4 FROM tab1 WHERE c1 = 1 AND c2 = 2 AND c4 = 'WA' -- all the columns in the index on tab1 appear -- in the way required for the Primary table, -- and all the columns in the -- other tables appear in the way required -- for a Secondary table SELECT DISTINCT tab1.c1, tab1.c3, tab1.c4 FROM tab1, tab2 WHERE tab1.c2 = 2 AND tab2.c2 = tab1.c2 AND tab2.c1 = tab1.c1
• | The columns in the ORDER BY list must be a subset of the columns in the
SELECT list. | |
• | All the columns in the ORDER BY list are sorted in ascending order. |
SELECT DISTINCT miles, meal FROM Flights ORDER BY meal
Note that these are not equivalent functions; this is simply an internal Derby transformation.SELECT DISTINCT miles, meal FROM Flights
• | The columns in the ORDER BY list must be a subset of the columns in the
select list of the left side of the union. | |
• | All the columns in the ORDER BY list must be sorted in ascending order
and they must be an in-order prefix of the columns in the target list of the
left side of the UNION. |
SELECT miles, meal FROM Flights UNION VALUES (1000, 'D') ORDER BY 1
SELECT flight_id, segment_number FROM Flights UNION SELECT flight_id, segment_number FROM FlightAvailability ORDER BY segment_number , flight_id
is the index on t1 with the smallest number of leaf pages, and the optimizer is free to choose that path.SELECT COUNT(*) FROM t1